Deoarece structurile de date din standardul de C++ erau prea simple și nu îl puteau ajuta chiar în toate situațiile, Gicu s-a hotărât să se apuce de zona de research pentru a nu se plictisi prea tare.
El este nemulțumit de modul în care este implementat un dicționar în C++ și vrea să propună în noul standard C++26 o structură nouă: un dicționar pentru intervale.
Concret, el vrea să se bazeze pe implementarea de std::map<K, V>, pe care să o extindă pentru a stoca aceeași valoare pentru o grupare consecutivă de chei.
Structura lui Gicu ar trebui să suporte următoarele operații:
assign(start, end, value)— toate cheile din dicționar din intervalul[start, end)vor avea valoareavalue;- supraîncărcare pe operatorul
[]— va întoarce valoarea asociată unei chei din dicționar.
Cerință
Pentru a avea o șansă să fie acceptată de comitetul de C++, el scrie o implementare generică pentru structura de date. Însă aceasta are câteva greșeli; sarcina voastră este să corectați sursa. Aceasta poate fi găsită aici sau în secțiunea „Atașamente” din lateral.
Reprezentare internă a datelor
Gicu dorește să realizeze din prima o implementare cât mai eficientă pentru a merge încrezător cu propunerea sa. De asta, el folosește o implementare de std::map în care va ține minte doar capătul de start al intervalului.
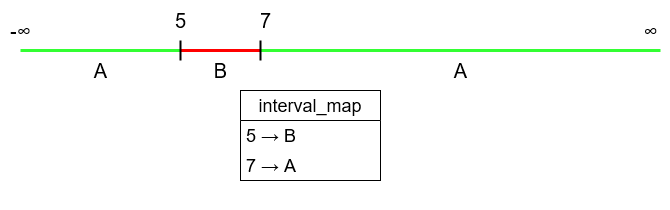
Inițial, toate cheile din dicționar au o aceeași valoare inițială, A.
Dacă dorește să seteze intervalul la valoarea B, în reprezentarea lui internă va adăuga în dicționar intrările (5, 'B') și (7, 'A').
Practic, fiecare pereche de tipul (key, value) din reprezentarea internă a dicționarului reprezintă faptul că de la cheia key până la următoarea cheie din dicționar (neinclusiv), toate valorile vor avea valoarea value.
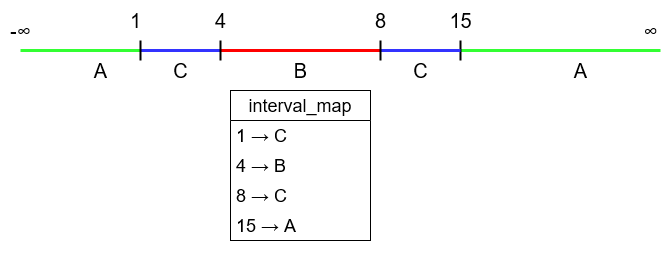
Să presupunem că la un moment dat structura interval_map cu cheile de tip int va conține: (1, 'C'), (4, 'B'), (8, 'C'), (15, 'A').
Atunci:
- pentru orice cheie între
INT_MINși inclusiv se va întoarce valoarea defaultA; - pentru cheile , , se va întoarce valoarea
C; - pentru cheile , , , se va întoarce valoarea
B; - pentru chei între și , inclusiv, se va întoarce valoarea
C; - pentru chei între și
INT_MAXse va întoarce valoareaA.
Un dicționar gol:
Un dicționar după aplicarea assign(5, 7, 'B'):
Un dicționar după mai multe inserții:
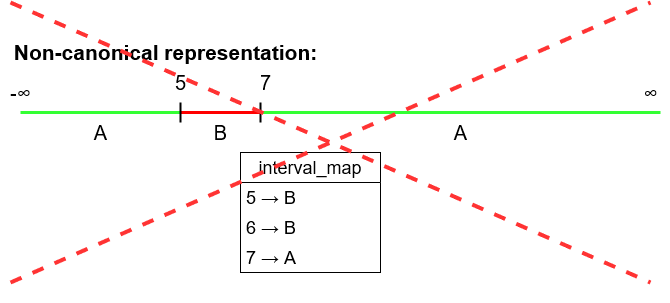
Un dicționar care nu este în forma canonică:
Testare manuală
Informațiile din această secțiune nu sunt necesare pentru a rezolva problema, ele au scopul de a facilita procesul de debugging.
Dacă aveți nevoie să afișați variabile template dintr-o metodă, va trebui să faceți o specializare a metodei.
O specializare este un mod de a preciza ce implementare să fie folosită pentru anumite instanțieri.
Documentația pentru asta este prezentă în reference/en/cpp/language/template_specialization.html, iar informațiile necesare sunt prezente în secțiunile Explicit specializations of function templates și Members of specializations.
Template-uri
Informațiile din această secțiune nu sunt necesare pentru a rezolva problema. Dar sunt de ajutor, pentru a înțelege contextul pentru codul sursă.
Un template reprezintă o sintaxă specială prin care definim o familie de clase sau funcții.
Prima secțiune specifică variabilele de template care pot fi folosite. Acestea vor putea înlocui tipurile de date din funcția sau clasa respectivă.
Codul scris într-o clasă template nu reprezintă o clasă reală, ci un prototip. Acesta poate fi transfomrat în mai multe clase, de compilator, atunci când template-ul este instanțiat.
De exemplu, cele trei declarări de mai jos reprezintă câte o instanțiere a template-ului, pentru clasa pair:
pair<int, int> a;
pair<char, int> b;
pair<char, long long> c;
În total sunt 3 instanțieri. Astfel, compilatorul va crea 3 clase pair diferite, care folosesc același prototip.
Mai multe informații despre template-uri: reference/en/cpp/language/templates.html.
Date de intrare
Pe prima linie se află numărul de operații ce vor fi efectuate asupra structurii.
Pe următoarele linii se va afla descrierea operațiilor. Operațiile pot fi de 3 tipuri:
- Operație de tip
0— se citesc 3 valoriinterval_start,interval_endșikeyreprezentând startul intervalului, finalul intervalului și cheia. - Operație de tip
1— se citește o cheiekeyși se afișează valoarea corespunzătoare acestei chei. - Operație de tip
2— se va afișa conținutul intern al dicționarului de intervale.
Citirea deja este făcută și nu conține probleme de implementare.
Date de ieșire
Se afișează pe ecran rezultatul pentru operațiile de tip 1 și 2.
Restricții și precizări
- Implementarea pentru dicționarul de intervale trebuie să fie canonică, adică două intrări consecutive din dicționarul de intervale trebuie să NU aibă aceeași valoare. Adică, nu e permis să avem un dicționar de intervale ce conține intrările consecutive
(5, 'A'),(8, 'A'). - Inițial, toate cheile din dicționarul de intervale vor avea o valoare primită în constructor.
- Nu ștergeți/modificați liniile marcate cu
DO NOT MODIFY. Nu inserați linii noi între liniile care formează un bloc continuu deDO NOT MODIFY. - Nu e permisă utilizarea caracterelor
[și]în implementarea voastră. - Variabilele
interval_startșiinterval_enddin operația0nu vor fiINT_MINsauINT_MAX. - Dacă toate valorile din interval au valoarea implicită, atunci ea nu o să apară în reprezentarea internă.
Exemplu
stdin
5
0 95 100 Z
0 57 64 A
0 17 52 P
0 18 55 R
2
stdout
17 P
18 R
55 A
95 Z
100 A
Explicație
Avem operații asupra structurii:
- operații de setare valori pentru intervale;
- o operație de afișare a reprezentării interne.
- Se setează valorile din intervalul la valoarea
Z; - Se setează valorile din intervalul la valoarea
A; - Se setează valorile din intervalul la valoarea
P; - Se setează valorile din intervalul la valoarea
R.